上一篇文章實作了簡單的 Retriever,那如果資料量越來越越多,或者是我的檔案是一個 PDF 檔的話,解析完的內容一多不可能存放在記憶體,所以有了今天的向量資料庫主題。
一般的資料庫都沒辦法存放向量資料,像是 MySQL 之類的,所以有向量資料庫的誕生。那麼向量資料庫有很多種,目前就我所知最比較主流的幾個分別是 AstraDB、Chroma、Milvus、MongoDB、Pinecone、Qdrant、Redis。但就我所知有些是需要付費的,像是 Pinecone 和 Milvus 好像都是,那麼今天的實作會以 Qdrant 為主,一樣是基於 LangChain 架構。
LangChain 支援的向量資料庫這邊 -> LangChain VectorStores
Qdrant 就跟市面上大多數資料庫一樣,有新增修改刪除查詢的基本功能,然後還有 filter 的篩選資料的功能 (支援聯集、交集)。Qdrant 的 collections 相當於一般資料庫的 table,payload 的功能相當於資料欄位,還有 metadata,然後 id 是 Primary Key 的概念,最後當然是可以儲存向量資料啦,可以儲存多筆的向量資料,圖片和文字的都可以。簡單分享一下選擇 Qdrant 的原因:
Qdrant 官網:Qdrant
Qdrant 有提供 Qdrant Cloud,但是只有 4GB。所以我們以本地安裝為主,可以透過 Docker 安裝在本機,安裝成功的話在 http://localhost:6333/dashboard 即可看到 Dashboard 介面。
# 從 Docker Hub 抓下 qdrant
docker pull qdrant/qdrant
# 啟動 qdrant
docker run -d --name qdrant -p 6333:6333 qdrant/qdrant
LangChain 框架的部分主要 Focus 在 Retriever 的部分,所以新增修改刪除查詢使用 Qdrant 自己的 qdrant-client 來編輯資料。
from langchain_ffm import FFMEmbedding
from qdrant_client import QdrantClient
from qdrant_client.http import models
from qdrant_client.http.models import VectorParams, Distance
embeddings = FFMEmbedding()
# 連線到資料庫
client = QdrantClient(url="http://localhost:6333")
# 如果 collections 不存在可以就建立一個 collections
if client.collection_exists(collection_name="test"):
pass
else:
client.create_collection(
collection_name="test",
# The TWCC embedding model has 1536 dimensions
vectors_config={
"text": VectorParams(
size=1536,
distance=Distance.COSINE,
),
},
)
# 欲匯入資料庫的資料
documents = [
"Python 是一種高階編程語言,近年來被拿來做許多機器學習和深度學習的開發與模型訓練。",
"Java 是一種面向對象的編程語言,廣泛應用於企業級應用和 Android 開發。",
"JavaScript 是網頁開發的核心語言,允許動態操作 DOM 以實現交互效果。",
"Go 是由 Google 開發的開源編程語言,因其高併發性能在雲端運算中大放異彩。",
"C# 是由微軟開發的語言,主要用於 Windows 應用開發及遊戲開發,特別是在 Unity 引擎中。",
"PHP 是一種伺服器端腳本語言,廣泛應用於網頁開發,尤其是動態內容生成。",
]
# 將資料全部匯入資料庫
for count, doc in enumerate(documents):
client.upsert(
collection_name="test",
points=[
models.PointStruct(
id=count+1,
vector={"text": embeddings.embed_query(doc)},
payload={"text": doc},
)
],
)
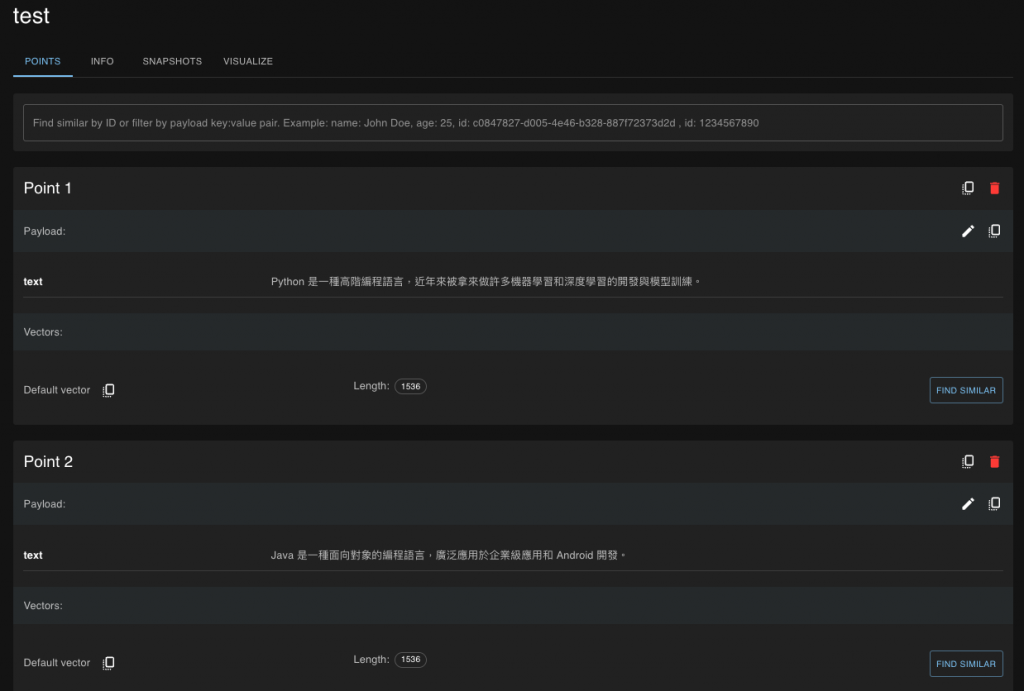
程式碼結果探討 🧐:
size 是文字 embeddings 之後的維度,譬如說台智雲是 1536、OpenAI 的 text-embedding-3-large 是 3072 等等distance 是進行 Retriever 時的比對方式,大多使用 Cosine Similarityupsert 即將資料匯入資料庫,id 就是 Primary Key 的概念,是不能重複的。vector 要與前面設定的名稱一致,維度也要一致。payload 就是可以加入自己想加的資料欄位。from langchain_qdrant import QdrantVectorStore
from langchain_ffm import FFMEmbedding
from qdrant_client import QdrantClient
from qdrant_client.http import models
from qdrant_client.http.models import VectorParams, Distance
from langchain_core.documents import Document
from uuid import uuid4
embeddings = FFMEmbedding()
# 欲匯入資料庫的資料
documents = [
Document(page_content="Python 是一種高階編程語言,近年來被拿來做許多機器學習和深度學習的開發與模型訓練。", metadata={"code":"Python"}),
Document(page_content="Java 是一種面向對象的編程語言,廣泛應用於企業級應用和 Android 開發。", metadata={"code":"Java"}),
Document(page_content="JavaScript 是網頁開發的核心語言,允許動態操作 DOM 以實現交互效果。", metadata={"code":"js"}),
Document(page_content="Go 是由 Google 開發的開源編程語言,因其高併發性能在雲端運算中大放異彩。", metadata={"code":"Go"}),
Document(page_content="C# 是由微軟開發的語言,主要用於 Windows 應用開發及遊戲開發,特別是在 Unity 引擎中。", metadata={"code":"C#"}),
Document(page_content="PHP 是一種伺服器端腳本語言,廣泛應用於網頁開發,尤其是動態內容生成。", metadata={"code":"PHP"}),
]
## 方法一
# 連線到資料庫
client = QdrantClient(url="http://localhost:6333")
# 如果 collections 不存在可以就建立一個 collections
if client.collection_exists(collection_name="ithome2024_method_1"):
pass
else:
client.create_collection(
collection_name="ithome2024_method_1",
# The TWCC embedding model has 1536 dimensions
vectors_config={
"text": VectorParams(
size=1536,
distance=Distance.COSINE,
),
},
)
# 建立 vector stores
vector_store = QdrantVectorStore(
client=client,
collection_name="ithome2024_method_1",
embedding=FFMEmbedding(),
vector_name="text",
)
# 將資料轉向量匯入資料庫,Primary Key 給 uuid
ids = [str(uuid4()) for _ in range(len(documents))]
vector_store.add_documents(documents=documents, ids=ids)
## 方法二
qdrant = QdrantVectorStore.from_documents(
documents,
embeddings,
url="localhost",
collection_name="ithome2024_method_2",
)
程式碼結果探討 🧐:
qdrant-client 去連線資料庫,而第二種方式指定本地端就可以自動上傳指定的地方,是最精簡的方式。from langchain_ffm import FFMEmbedding
from langchain_qdrant import QdrantVectorStore
embeddings = FFMEmbedding()
# 可以直接連線建立好的 collections
vector_store = QdrantVectorStore.from_existing_collection(
url="http://localhost:6333",
collection_name="ithome2024_method_1",
embedding=embeddings,
vector_name="text",
)
# Cosine Similarity 的 Retriever
cos_retriever = vector_store.as_retriever(search_type='similarity', search_kwargs={'k': 2})
print("這邊是 Cosine Similarity:")
result = cos_retriever.invoke('我想成為前端工程師!')
print(result[0].page_content, result[1].page_content)
result = vector_store.similarity_search(query='我想成為前端工程師!', k=2)
print(result[0].page_content, result[1].page_content)
# MMR 的 Retriever
mmr_retriever = vector_store.as_retriever(search_type='mmr', search_kwargs={'k': 2, 'lambda_mult': 0.25})
print("\n這邊是 MMR:")
result = mmr_retriever.invoke('我想成為前端工程師!')
print(result[0].page_content, result[1].page_content)
result = vector_store.max_marginal_relevance_search(query='我想成為前端工程師!', k=2, lambda_mult=0.25)
print(result[0].page_content, result[1].page_content)

程式碼結果探討 🧐:
若是今天想要匯入資料庫之後針對其進行索引的話,那麼 LangChain 可以完成這件事情。不需要先匯入,然後找 collections 這麼麻煩,接下來來實戰!
from langchain_ffm import FFMEmbedding
from langchain_qdrant import QdrantVectorStore
from langchain_core.documents import Document
embeddings = FFMEmbedding()
# 欲匯入資料庫資料
documents = [
Document(page_content="Python 是一種高階編程語言,近年來被拿來做許多機器學習和深度學習的開發與模型訓練。", metadata={"code":"Python"}),
Document(page_content="Java 是一種面向對象的編程語言,廣泛應用於企業級應用和 Android 開發。", metadata={"code":"Java"}),
Document(page_content="JavaScript 是網頁開發的核心語言,允許動態操作 DOM 以實現交互效果。", metadata={"code":"js"}),
Document(page_content="Go 是由 Google 開發的開源編程語言,因其高併發性能在雲端運算中大放異彩。", metadata={"code":"Go"}),
Document(page_content="C# 是由微軟開發的語言,主要用於 Windows 應用開發及遊戲開發,特別是在 Unity 引擎中。", metadata={"code":"C#"}),
Document(page_content="PHP 是一種伺服器端腳本語言,廣泛應用於網頁開發,尤其是動態內容生成。", metadata={"code":"PHP"}),
]
# 匯入 Qdrant
qdrant = QdrantVectorStore.from_documents(
documents,
embeddings,
url="http://localhost:6333",
collection_name="ithome2024",
force_recreate=True
)
# Retriever 結果
for result in qdrant.similarity_search(query='我想成為前端工程師!'):
print(result.page_content)

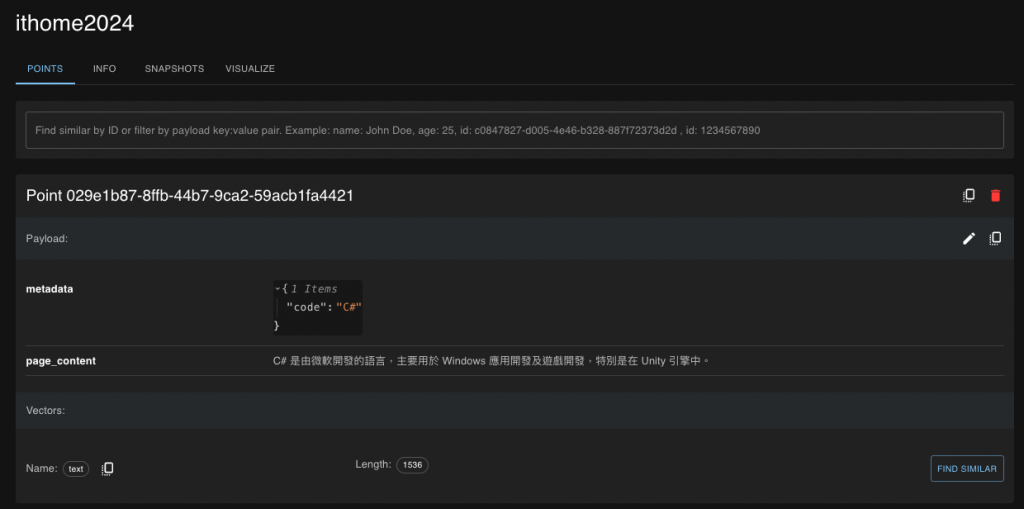
程式碼結果探討 🧐:
force_recreate,資料自動向後增加。今天簡單實作了 Qdrant 資料庫,雖然我除了 Qdrant 還沒有用過別的,但我覺得在 LangChain 架構下,每個資料庫被整合進來語法應該都不會差太多。我自己未來會想實作 MongoDB 和 Pinecone 之類的向量資料庫,有時間再來試試看吧!
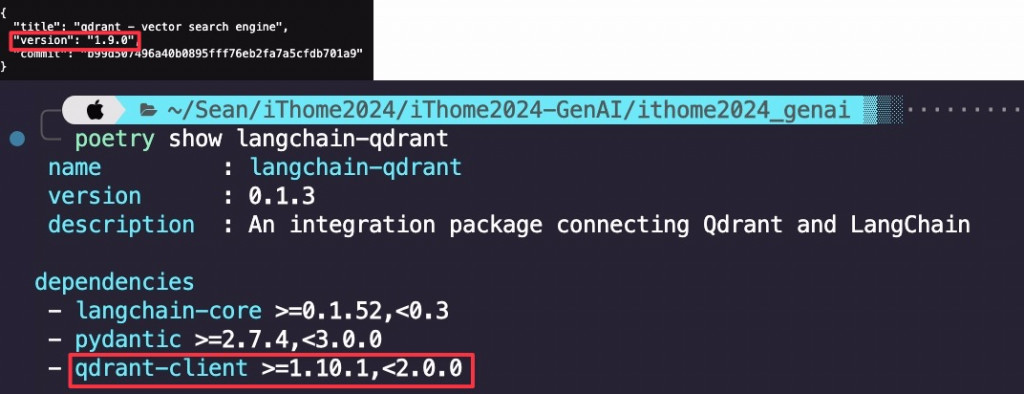
如果大家要使用 Qdrant 的話,記得看看langchain-qdrant支援的版本有沒有包含你本機的版本,我因為這個 bug 一直 error,但他根本沒顯示是版本問題。
今天一整天開了一堆的會議,上班八小時有七小時在開會,在迷迷糊糊中度過了今天的上班時光。